E-commerce Data Analytics
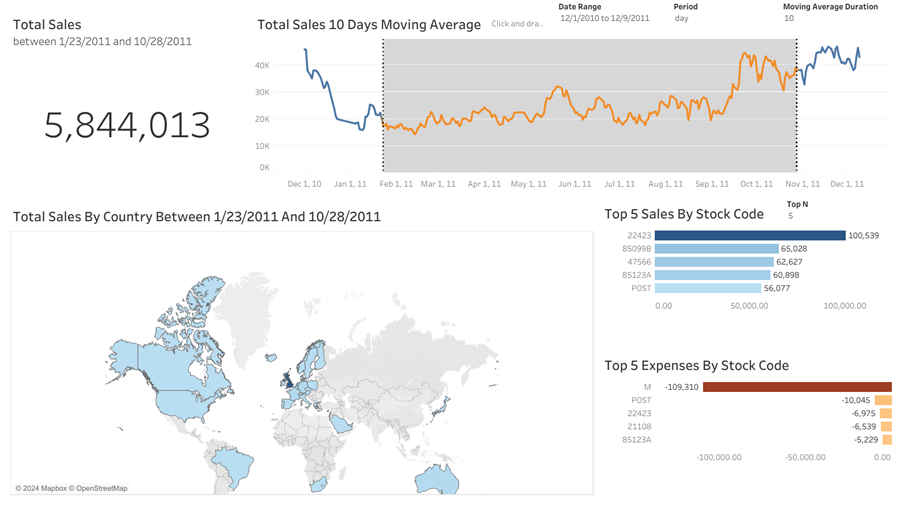
In this project, we will explore an e-commerce dataset using Python for data exploration and cleaning as well as Tableau to create a dashboard. The dataset can be found here. You can jump directly and try the interactive dashboard here 🚀
import pandas as pd
df = pd.read_csv('./data/e-commerce.csv', encoding="ISO-8859-1")
print(df.head().to_markdown())
| | InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country |
|---:|------------:|:------------|:------------------------------------|-----------:|:---------------|------------:|-------------:|:---------------|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 12/1/2010 8:26 | 2.55 | 17850 | United Kingdom |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 12/1/2010 8:26 | 3.39 | 17850 | United Kingdom |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 12/1/2010 8:26 | 2.75 | 17850 | United Kingdom |
| 3 | 536365 | 84029G | KNITTED UNION FLAG HOT WATER BOTTLE | 6 | 12/1/2010 8:26 | 3.39 | 17850 | United Kingdom |
| 4 | 536365 | 84029E | RED WOOLLY HOTTIE WHITE HEART. | 6 | 12/1/2010 8:26 | 3.39 | 17850 | United Kingdom |
By looking at the sample data above, we can see the dataset contains e-commerce transaction fields such as invoice number, stock code and customer ID. It is great to see there is a country column to create a map in our dashboard.
Let’s explore the data further by getting basic statistics for numerical values.
print(df.describe().T.to_markdown())
| | count | mean | std | min | 25% | 50% | 75% | max |
|:-----------|--------:|------------:|----------:|---------:|---------:|---------:|---------:|------:|
| Quantity | 541909 | 9.55225 | 218.081 | -80995 | 1 | 3 | 10 | 80995 |
| UnitPrice | 541909 | 4.61111 | 96.7599 | -11062.1 | 1.25 | 2.08 | 4.13 | 38970 |
| CustomerID | 406829 | 15287.7 | 1713.6 | 12346 | 13953 | 15152 | 16791 | 18287 |
There is something strange for ‘Quantity’ and ‘UnitPrice’ column: the minimum value is negative. To see sample rows for these negative values:
print(df[df.UnitPrice < 0].head().to_markdown())
| | InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country |
|-------:|:------------|:------------|:----------------|-----------:|:----------------|------------:|-------------:|:---------------|
| 299983 | A563186 | B | Adjust bad debt | 1 | 8/12/2011 14:51 | -11062.1 | nan | United Kingdom |
| 299984 | A563187 | B | Adjust bad debt | 1 | 8/12/2011 14:52 | -11062.1 | nan | United Kingdom |
From the description, it is now known that the negative unit price accounts for the debt, which makes sense. Let’s do the same for quantity:
print(df[df.Quantity < 0].head().to_markdown())
| | InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country |
|----:|:------------|:------------|:--------------------------------|-----------:|:----------------|------------:|-------------:|:---------------|
| 141 | C536379 | D | Discount | -1 | 12/1/2010 9:41 | 27.5 | 14527 | United Kingdom |
| 154 | C536383 | 35004C | SET OF 3 COLOURED FLYING DUCKS | -1 | 12/1/2010 9:49 | 4.65 | 15311 | United Kingdom |
| 235 | C536391 | 22556 | PLASTERS IN TIN CIRCUS PARADE | -12 | 12/1/2010 10:24 | 1.65 | 17548 | United Kingdom |
| 236 | C536391 | 21984 | PACK OF 12 PINK PAISLEY TISSUES | -24 | 12/1/2010 10:24 | 0.29 | 17548 | United Kingdom |
| 237 | C536391 | 21983 | PACK OF 12 BLUE PAISLEY TISSUES | -24 | 12/1/2010 10:24 | 0.29 | 17548 | United Kingdom |
There are a few interesting findings here. Firstly, there is a unique stock code ‘D’ which is different from the rest. There could be other unique stock codes in the dataset that represent special meanings like in this case. Secondly, the invoice number contains ‘C’ prepended to the numbers. This could mean cancellations as it is common for buyers to return the purchased goods. It explains why for these rows, the quantity is negative.
If we want to find unique stock codes:
df["StockCodeNumericLen"] = df.StockCode.apply(lambda code: sum(1 for c in code if c.isdigit()))
df[df.StockCodeNumericLen != 5].Description.value_counts()
Description
POSTAGE 1252
DOTCOM POSTAGE 709
Manual 572
CARRIAGE 143
Discount 77
SAMPLES 63
Bank Charges 37
AMAZON FEE 34
CRUK Commission 16
GIRLS PARTY BAG 13
BOYS PARTY BAG 11
Dotcomgiftshop Gift Voucher £20.00 9
Dotcomgiftshop Gift Voucher £10.00 8
Dotcomgiftshop Gift Voucher £30.00 7
ebay 5
BOXED GLASS ASHTRAY 4
PADS TO MATCH ALL CUSHIONS 4
Dotcomgiftshop Gift Voucher £50.00 4
Dotcomgiftshop Gift Voucher £40.00 3
Adjust bad debt 3
SUNJAR LED NIGHT NIGHT LIGHT 2
CAMOUFLAGE DOG COLLAR 1
OOH LA LA DOGS COLLAR 1
HAYNES CAMPER SHOULDER BAG 1
to push order througha s stock was 1
Name: count, dtype: int64
The code above counts the digit in the stock code. Then we find rows that have stock code digit other than 5. Looking at the result, we can get better ideas for the meaning of these special codes. However, it appears there are standard products that are included in the non-standard stock codes such as ‘HAYNES CAMPER SHOULDER BAG’.
As we want to analyze both the total sales and expenses in the dashboard, these special codes are not removed from our dataset. It is still useful to keep the existence of these non-standard codes in mind nonetheless.
Missing Values
The next procedure is to find missing values. We can find the percentage of null values in each column like so:
df.isnull().sum() / df.shape[0] * 100
InvoiceNo 0.000000
StockCode 0.000000
Description 0.268311
Quantity 0.000000
InvoiceDate 0.000000
UnitPrice 0.000000
CustomerID 24.926694
Country 0.000000
dtype: float64
About 25% customer IDs are missing, which makes the rows redundant in our case. We only want to count for valid purchases that can be considered by having a customer ID.
There are also rows with missing description. This depends on each scenario but in this case we keep these rows as it is assumed that the description can be added in the future by looking at the stock code.
df = df.dropna(subset=['CustomerID'])
df.isnull().sum().sum()
0
It turns out that by removing the missing customer ID, missing description is taken care of too.
Duplicates
Finding duplicate entries is an important task because we want to avoid double counting.
To validate duplicated rows, we can get sample rows where multiple fields have identical values.
print(df[df.duplicated(keep=False)].sort_values(by=['InvoiceNo', 'InvoiceDate', 'StockCode', 'Description', 'CustomerID']).head().to_markdown())
| | InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | StockCodeNumericLen |
|----:|------------:|------------:|:------------------------------|-----------:|:----------------|------------:|-------------:|:---------------|----------------------:|
| 494 | 536409 | 21866 | UNION JACK FLAG LUGGAGE TAG | 1 | 12/1/2010 11:45 | 1.25 | 17908 | United Kingdom | 5 |
| 517 | 536409 | 21866 | UNION JACK FLAG LUGGAGE TAG | 1 | 12/1/2010 11:45 | 1.25 | 17908 | United Kingdom | 5 |
| 485 | 536409 | 22111 | SCOTTIE DOG HOT WATER BOTTLE | 1 | 12/1/2010 11:45 | 4.95 | 17908 | United Kingdom | 5 |
| 539 | 536409 | 22111 | SCOTTIE DOG HOT WATER BOTTLE | 1 | 12/1/2010 11:45 | 4.95 | 17908 | United Kingdom | 5 |
| 489 | 536409 | 22866 | HAND WARMER SCOTTY DOG DESIGN | 1 | 12/1/2010 11:45 | 2.1 | 17908 | United Kingdom | 5 |
By assessing the sample rows, the detected duplicates indeed have identical column values. This can lead to inaccurate aggregation in the future. Hence, these duplicates need to be dropped.
df = df.drop_duplicates()
df.shape[0]
401604
From more than 500 thousands rows, the final data consists of ~400 thousands rows. We can then save the cleaned data into a csv file to be used in our dashboard.
df.to_csv('./data/e-commerce-cleaned.csv', index=False)
Done! You can access the Tableau dashboard here